There are 300+ databases in the market. However, there are few databases developed specifically for machine learning. There is one product called MLDB which is an open-source database for ML. However, the company behind the database was acquired by Element AI. Kinetica is another startup that’s developed a database for machine learning data analytics that spreads compute workload across GPUs and CPUs simultaneously.
The Kineteca database works in memory just like Apache Spark. In-memory databases are considerably faster than those that work purely off of the disk. Kinetica refers to their database as a “vectorized, columnar, memory- first database designed for analytical (OLAP) workloads” that “automatically distributes any workload across CPUs and GPUs for optimal results”.
Thus, Kinetica is able to spread the AI workloads across CPUs and GPUs, reducing the overall system cost since GPU cards are expensive. The Kinetica architecture is illustrated below.
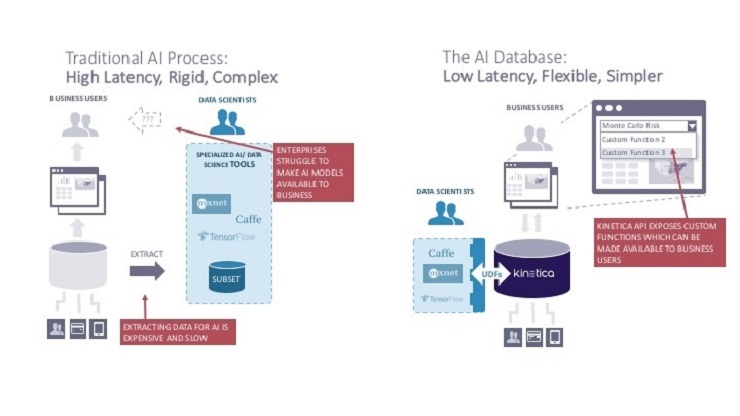
In a white paper, Kinetica explains one of the benefits of their system architecture – it places computationally heavy processes on the GPUs and the less compute-intensive processes on the CPUs. In addition, it will leverage the RAM on the motherboard and the memory on the GPU cards to optimize performance.
In addition, using the column-based approach, Kinetica is able to use storage more efficiently in a data analytics environment and provide fast query performance. The one caveat, the GPU database is not for training ML models. For training, Apache Spark is the better product.
2 Important Features
- Spread processing load across GPU’s and CPU’s
- GPU memory and system RAM is used to process and store data for AI tasks
The Consumption Model
IDC Research Director Sriram Subramanian published an article on the modern AI stack that describes the different consumption models. Although he doesn’t explain a database for machine learning, different layers of the AI stack including compute and data are illustrated below.
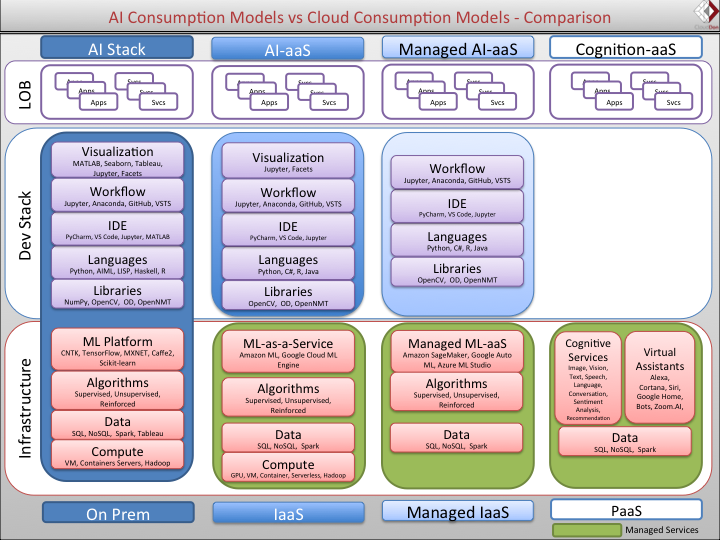
Sriram breaks down the consumption model into four different types. In the the on-prem column, the compute layer is at the bottom of the stack and the data layer is right above it. However, for ML training, compute takes place in the GPU and CPUs. The server type would be the type of system being used for ML, such as dedicated server, container, VM, or shared server, perhaps?
Important Questions
- Is a database even required for ML training
- Can a file system like Hadoop take the place of a database strickly for model training and inference (after training is complete)
Apache Kafka
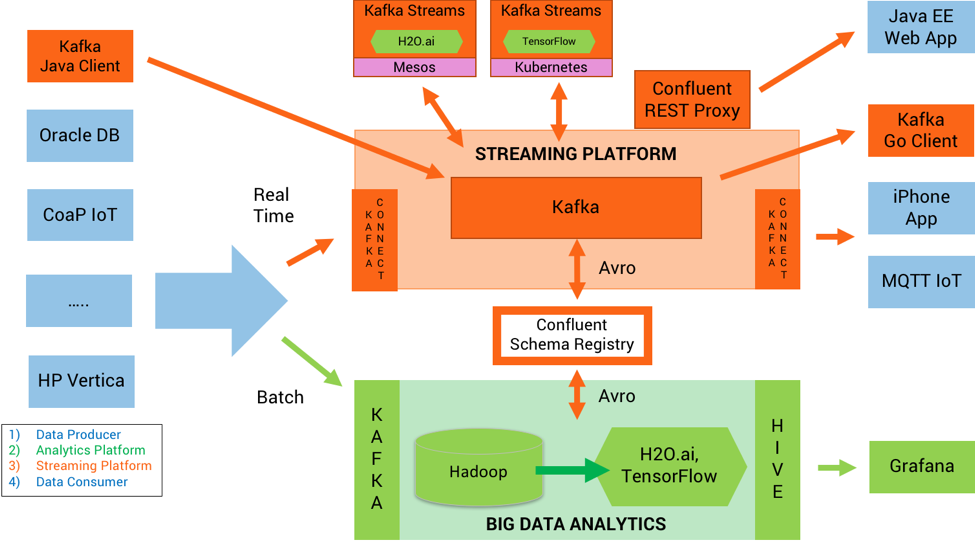
Apache Kafka is a popular stream processing engine, designed to work as a highly scalable system that can process a high volume of real-time data feeds. The Kafka parts include the 1) producers 2) cluster and 3) consumers. All three parts allow companies to ingest, process, and output data in an organized manner. LinkedIn originally developed Kafka, then donated it to the Apache Foundation. The developers of Kafka left LinkedIn and created a company called Confluence, which focuses on Kafka.
Confluent Tech Evangelist Kai Waehner created a reference architecture and an ML Development Lifecycle which is illustrated below. On the left-hand side are the systems that provide data to Kafka and Hadoop. Kafka ingests real-time data and Hadoop batch data. TensorFlow and H20.ai sit right next to Hadoop. Hadoop is not a database but distributed file system that works efficiently across large clusters of commodity servers. However, the article and architecture do not provide enough depth to form any kind of opinion or conclusion.
In summary, there’s a need for more databases developed for machine learning.