In the world of big data and machine learning, there are some tools that can be used for either use case. When it comes to big data, popular tools are Hadoop, MapReduce, and Spark. However, they’re also suitable for machine learning. A few years ago, Hadoop was the de facto open source technology for big data. However, interest is waning especially as data cloud providers such as Snowflake make it easy to work with data cost-effectively.
Hadoop is an important building block to some organizations because it’s highly scalable and redundant. Thus, the processing of large data volumes can be distributed among any size cluster of commodity servers.
Hadoop is a framework comprising of multiple features but at its core, it’s a distributed file system. MapReduce sits on top of Hadoop and provides processing capabilities, working with both structured and unstructured data. However, MapReduce has many imitations, thus the reason Spark came about.
In 2015, computer Scientist Matel Zaharia created Spark while at UC Berkeley. In general, Spark is a better product than MapReduce for the following reasons: 1) It runs in-memory so it’s faster than MapReduce, which relies on disk 2) Spark runs on many different platforms including Kubernetes 3) Spark works with batch and real-time data (stream) processing, whereas MapReduce works only with batch processing and 4) the Spark ecosystem is growing, and libraries like MLib have been developed for it. Spark MLib is a popular machine learning library that supports NumPy-like computations and comes with different algorithms. Most importantly, Spark has the ability to distribute ML workloads across different resources.
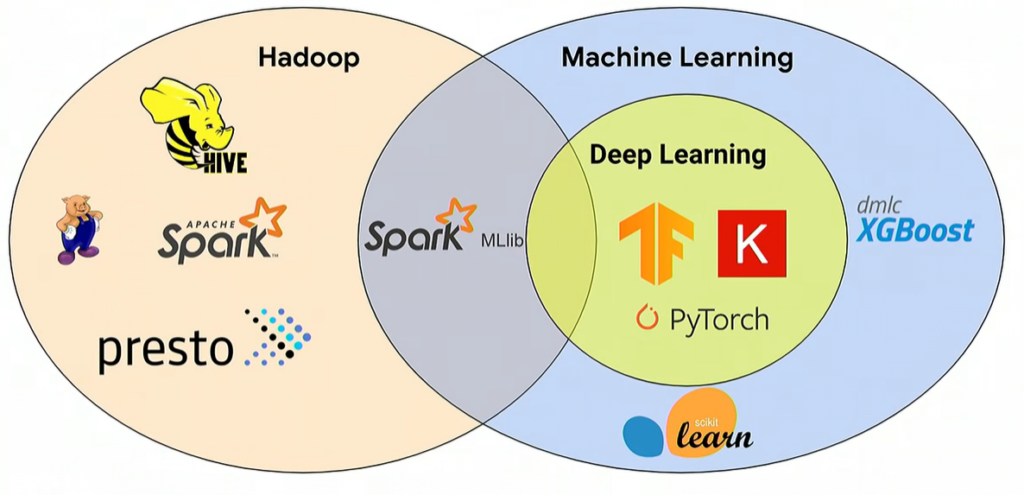
Apache Spark and TensorFlow
The three primary phases in machine learning are data preparation, training, and inference. Training requires more computing resources than inference because data is flowing forward and backward between layers numerous times until model accuracy reaches a set objective. Training time can take anywhere from hours to weeks depending on the size of the dataset and complexity of the model (# of layers and neurons). Therefore, reducing training time is key for bringing models to production faster. In the graphic below, there are four layers and ten neurons in this deep learning model. In terms of model complexity, it sits somewhere between simple and complex.
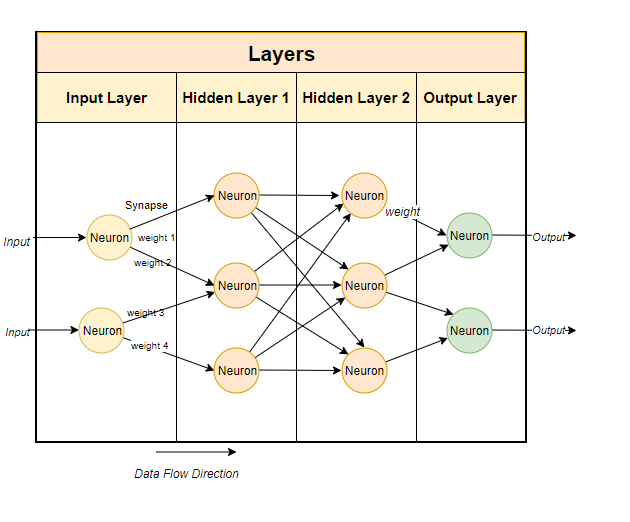
Google Example
Google machine learning engineer Gonzalo Gasca Meza describes one method for reducing training time using distributed machine learning. When it comes to model experimentation, a best practice is to run tasks in parallel, such as hyperparameter searching (tuning) on different nodes. This is especially true when working with large datasets and the volume of data being worked on is greater than the capacity of a single node. TensorFlow allows tasks to be broken up and distributed on different machines for processing in order to accelerate training time.
When experimentation moves to production, ML pipelines come into play. Gonzalo breaks down the ML process into three phases: data preparation, training, and service.
- Data Preparation: This involves feature engineering and ETL. The primary job here is to collect data and create features that represent the data in a table. A GPU is not needed for this phase, thus a CPU cluster should work. Apache Spark comes into play in this phase.
- Training: After data is prepared, training takes place. GPU clusters should be used in this phase. Also, a resource manager is needed to assign the workloads to the GPUs.
- Serving: After training is complete, the model graduates to production. Workloads can be distributed among CPUs and GPUs. Also, workloads can run on Kubernetes or Docker. More GPUs can be added to improve performance.
Other Tools
There are other tools that play an important role in machine learning such as the resource manager and job scheduler. YARN, created for Hadoop is a resource manager and job scheduler that allocates resources in a cluster.
In the latest version of Hadoop (3.1x) and YARN, there is first-class support for GPUs. Thus, YARN is able to schedule resources to run on GPUs, regardless of volume. Another tool is Kubeflow which simplifies the deployment of machine learning workflows on Kubernetes. However, it doesn’t support Hadoop. This is where TFS comes into play. TensorFlowOnSpark (TFS) supports deep learning models that run on Apache Spark and Hadoop. Yahoo developed this product in order to scale deep learning models so they run efficiently on GPU and CPU clusters.
TonY
TonY is a deep learning framework developed by LinkedIn. It “natively runs deep learning jobs on Apache Hadoop.” As illustrated in the chart above, TonY is the only product that runs on Hadoop, supports GPUs, and has native YARN support. In addition, it supports the following frameworks: PyTorch, TensorFlow, MXNet, and Horovod. With the latest Hadoop and YARN versions, workloads can be distributed across GPUs and servers.
In summary, Hadoop, Spark, and YARN can be used in machine learning models.