When building an AI stack, emphasis must be given to tasks that perform data ingest, parallel processing, stream processing, distributed computing (workloads), and storage. In ML, parallel processing is different than stream processing. Kafka and Spark Streaming (Spark extension) are stream processors that ingest data from server logs, IoT devices, sensors, and so on. Then they transform it into a more useful format that can be outputted to another system.
AI frameworks like TensorFlow and Pytorch have out-of-the-box capabilities that perform parallel processing, breaking down tasks into parts, then distributing the workloads across multiple GPUs, and nodes.
Using TensorFlow with Spark
Founded in 2013, Databricks is the company behind Apache Spark. Tim Hunter, a Ph.D. and software engineer with Databricks has authored an article in which he describes the benefits of using Spark with TensorFlow. Apache Spark (not Spark Streaming) can be used to scale TensorFlow workloads during model training and inference (trained).
For model training, Spark is useful for scaling hyperparameter tuning. Hyperparameter tuning falls under the umbrella term Model Optimization. Google describes the same process as “Hyperparameter Optimization”. Thus, the process of tuning the right parameters in every model is of vital importance, in that it impacts the performance and accuracy of a model.
Jesus Rodriguez, CTO at IntoTheBlock writes that “entire branches of machine learning and deep learning theory have been dedicated to the optimization of models” and “optimization often entails fine-tuning elements that live outside the model but that can heavily influence its behavior”. Thus, hyperparameters are the hidden elements in deep learning models that can be fined tuned in order to control behavior. TensorFlow and other models come with basic hyperparameters such as learning rate, however, the process of finding the best hyperparameters for a given model involves experimentation and manual effort.
Hyperparameter Examples
- IntoTheBlock: 1) Learning rate 2) # of hidden units 3) Convolution Kernal Width
- Google: 1) Learning rate 2) dropout rate in dropout layer 3) # of units in the first dense layer 4) optimizer
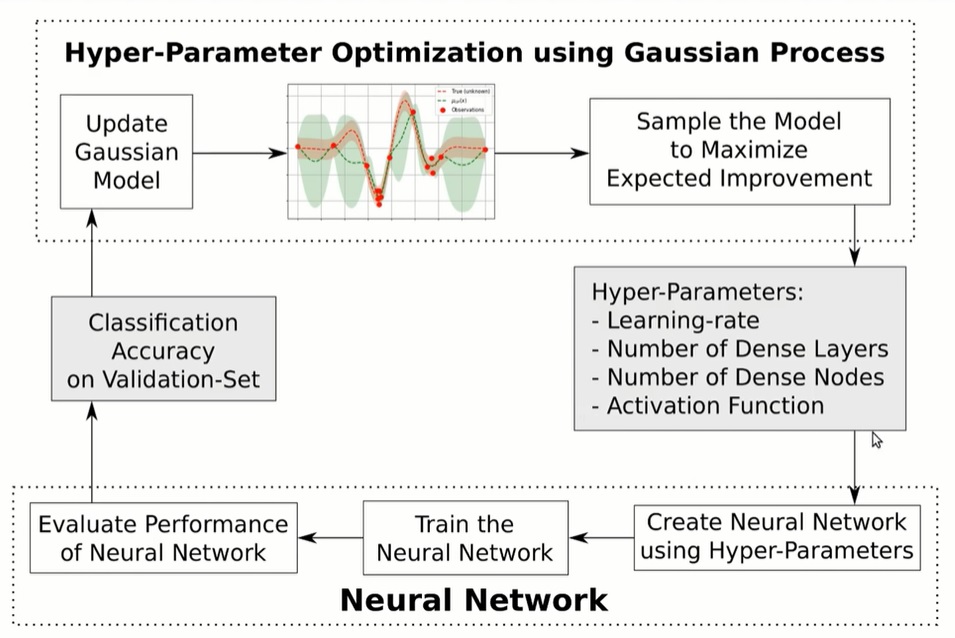
- Hvass Labs: 1) Learning rate 2) # of dense layers 3) # of dense nodes 4) activation function
In one example, Hvaas Labs outlines the steps of hyperparameter optimization for a particular model using the “Gaussian Process” and TensorFlow.
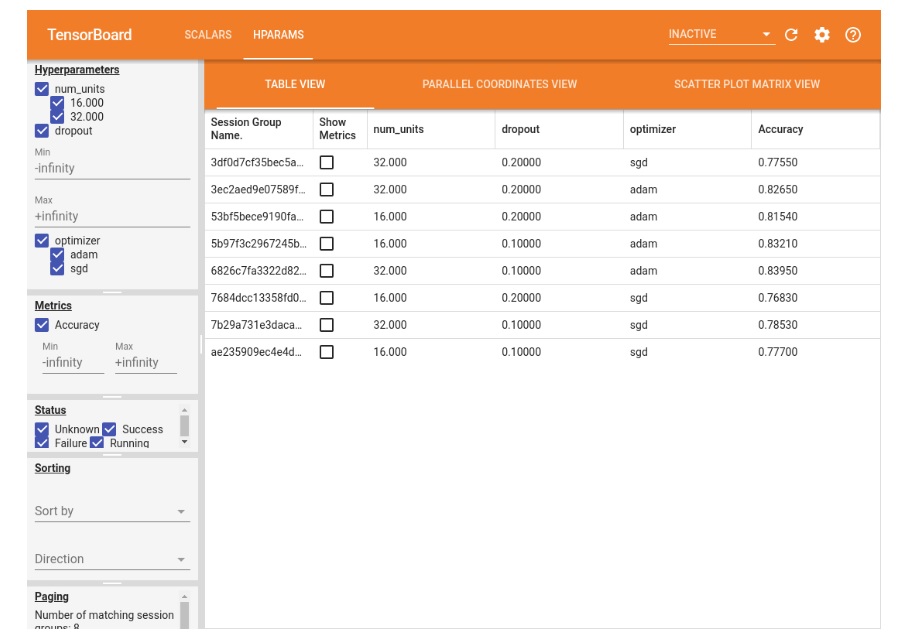
In another example, Google displays three hyperparameters on TensorBoard for a particular model which include 1) num_units 2) dropout, and 3) optimizer.
In the Databricks article, the author describes the process of transforming an image such as the “classical” NIST dataset into digits so a machine learning model can read it. Using TensorFlow, the tool is able to read the image, then perform the mathematical computation to turn the pixels of the image into “signals” that are read by the algorithm. Although TensorFlow creates training algorithms, the more difficult part is selecting the right hyperparameters. If the right parameters are selected, the model performs well. If the wrong ones are selected, model performance suffers.
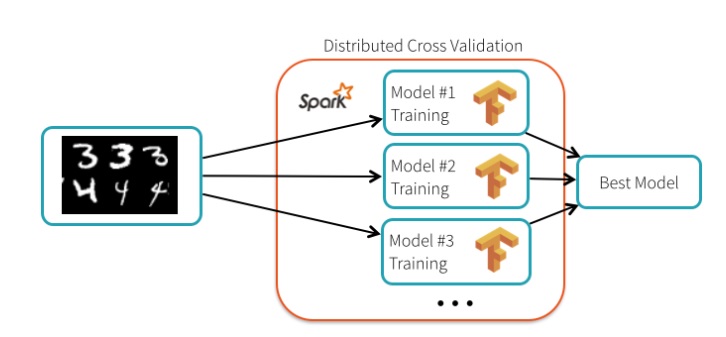
Interestingly, the author explains that “TensorFlow itself is not distributed, the hyperparameter tuning process is embarrassingly parallel and can be distributed using Spark”. However, Google engineer Gonzalo Meza states that TensorFlow “doesn’t really care about the underlying infrastructure” because there is a feature called tf.distribute.Strategy that allows the “TensorFlow API to distribute training across multiple GPUs, multiple machines or TPUs.” In other words, TensorFlow is “embarrassingly parallel” out of the box.
In a hyperparameter tuning test, Databricks set up a 13-node cluster to perform the test. The Databricks team was able to achieve a 99.47% accuracy rate, which was 34% better than running the default settings for TensorFlow. Each node ran a different model, thus training in parallel was accomplished.
Scaling TensorFlow and PyTorch
TensorFlow and PyTorch have native support for distributed machine learning. TensorFlow has an API called tf.distribute.Strategy that allows training workloads to be spread across nodes, TPUs, and GPUs. The distribute.Strategy benefits include the following:
- Scales from 1 node to multiple nodes and GPUs/TPUs
- Supports multiple user groups
- Improves performance “out of the box”
- Can be used with Keras
- Supports synchronous and asynchronous training
- Synchronous: “all workers train over different slices of input data in sync, and aggregating gradients at each step”
- Asynchronous: “all workers are independently training over the input data and updating variables asynchronously”
- Six strategies are supported: 1) MirroredStrategy 2) TPUStrategy 3) MultiWorkderMirroredStrategy 4) CentralStorageStrategy 5) ParameterServerStrategy and 6) OneDeviceStrategy PyTorch has a feature called DataParallel which is a “distributed training technique” that allows training to be replicated across different GPUs on the same node to accelerate training. Another PyTorch feature is Model Parallel which “splits a single model onto different GPUs, rather than replicating the entire model on each GPU”. One example is given – if a model contains 10 layers (input + output + 8 hidden), each layer can be placed on a GPU on different devices. If one machine is used with 2 GPUs, then 5 layers can be processed on each GPU.
Stream Processing
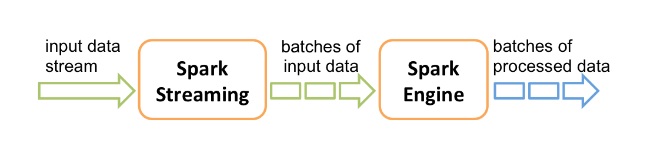
Now we can discuss another type of processing called stream processing. Stream processing involves the ingest and processing of live data streams. The data streams can be anything from weblogs to IoT device data to sensor data, and so on. Two popular stream processors are Kafka and Apache Spark Streaming. Both tools will be used in our reference architecture. Spark Streaming and Kafka are relatively well known and used by thousands of companies worldwide. Spark Streaming is an extension of Spark and provides stream process capabilities to Spark since it doesn’t support that natively.
As illustrated in the diagram below, Spark Streaming ingest real-time data streams from a data source, then breaks those streams into batches called RDDs. The collection of RDD batches is the DStream which represents the “continuous stream of data”. Thereafter, the RDD’s are fed into Spark. From there, the data can undergo a further transformation or be fed into another system like a database or ML model.
Spark Streaming
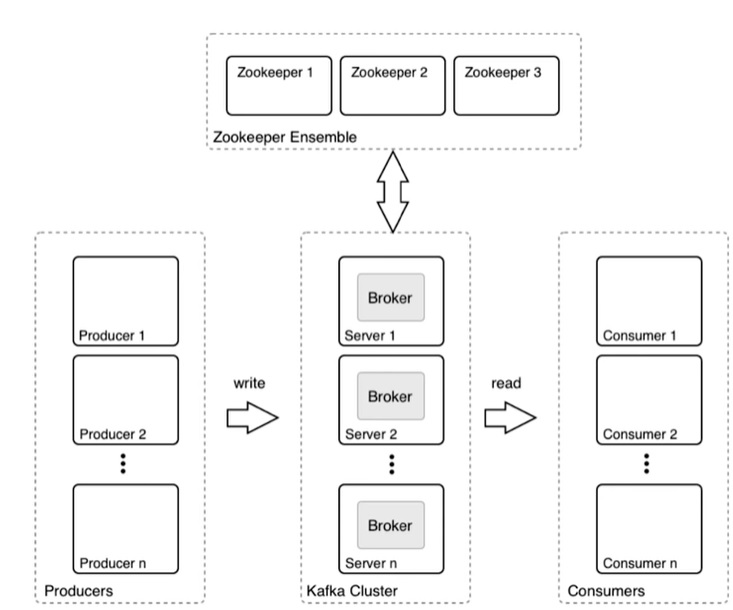
Kafka is the more robust system of the two. In the graphic below, the Kafka parts are illustrated. The producer is any application or system that generates raw data such as an IoT device, web server, database, router, etc. The Kafka cluster ingests the raw data from the producer, queues it if the volume of data is high, then forwards it to the consumer who subscribes to the Topic. The Topic is the name of the feed or category of data.
In summary, there are stacks available to help with data ingest, parallel processing, stream processing, distributed computing, and storage.