Feature engineering is the preparation of raw data that is to be used in the machine learning model. In machine learning, there are two types of data, inputs, and outputs. Regardless of the model being used, inputs are fed into the model and outputs are the results.
In supervised learning, the inputs and outputs are known. Thus, a human guides the model until predictions are highly accurate. In unsupervised learning, the inputs are known but not the outputs. The algorithm must identify patterns in the data, detect anomalies, then make predictions on its own. Semi-supervised learning is a combination of both.
The success of the model depends on the quality of the inputs. The data structure of the inputs is usually laid out in rows and columns. The values in the columns are features of the data, and feature engineering is the preparation of the features and dataset. Jason Brownlee, Ph.D., data scientist, and well-known blogger states that feature directly impact the results the model can achieve. Creating ideal features in any model requires domain knowledge and creativity. Many startups and cloud providers are automating the process of feature engineering.
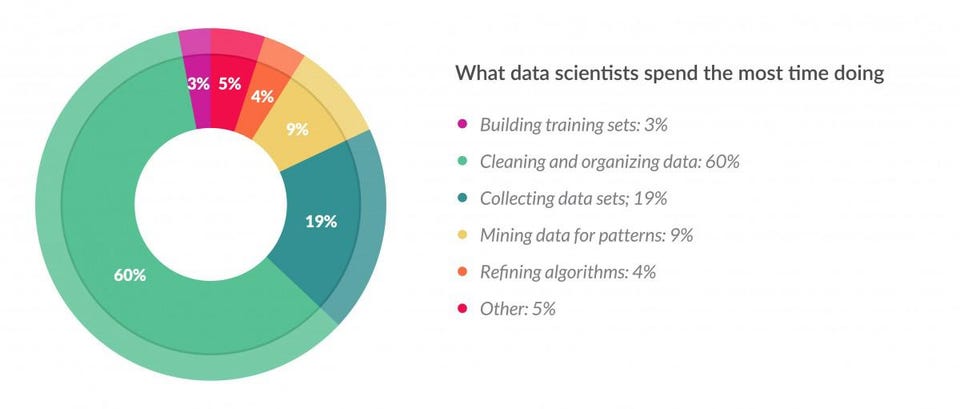
One of the problems that occur when exporting data into a spreadsheet or file is that some fields will have missing values. Tools and techniques can be used to clean up the data so it’s consistent across the board. Generating highly accurate predictions depends on it. According to Forbes, CrowFlower conducted a survey of data scientists and found that data preparation accounts for 80% of the work.
Although feature engineering is important in creating the right model, Blogger Jason Brownlee states that results achieved in a model depend on the features, model, data, and the framing of the objectives. In other words, creating a high-performance machine learning model depends on picking the right algorithm, data quality, creating the right features, and asking the right questions.
Techniques of Feature Engineering
Emre Rencberoglu, a data scientist lists nine techniques for feature engineering. Some techniques are better than others. In terms of which one to use in a particular model depends on the use case. Emre included Python scripts for every technique in his blog post. All that is required is the installation of NumPy and pandas. Both are critical Python packages for data scientists. They allow developers to create multi-dimensional array objects. NumPy (Numerical Python) is a Python library that comes packed with math functions and provides fast mathematical computation on arrays and matrices. On a side note, NumPy, Scikit-learn, Matplotlib, TensorFlow, Pandas, and other tools create the “Python Machine Learning Ecosystem.”
Nine Feature Engineering Techniques
- Imputation: Deals with missing values, which is the result of human error, data flow disruptions, etc. Some programs drop rows with missing values while others don’t accept datasets with missing values. Emre believes it’s best to drop the rows or columns with missing values. Here is the Python code that fixes the problem with missing values. Ignore the beginning letters.
- threshold = 0.7
#Dropping columns with missing value rate higher than threshold
data = data[data.columns[data.isnull().mean() < threshold]]
#Dropping rows with missing value rate higher than threshold
data = data.loc[data.isnull().mean(axis=1) < threshold]
- threshold = 0.7
- Handling Outliers: The best way to handle an outlier (detached data) is to plot it on a graph. Two statistical methods for working on outliers are standard deviation and percentiles.
- Binning: The grouping of numerical data into bins, also known as quantization. Useful in cases when columns have values that are too many to create a model for. Also helpful when values fall outside expected ranges (normal distribution).
- Log Transform: Commonly used for mathematical transformation. Technique is able to changed skewed data into a normal distribution. The technique also minimizes the impact of outliers, helping the model becomes more robust.
- One-Hot Encoding: Encoding method that assigns 0 and 1’s to values in a column. Methods alter data to a numerical format that might be easier for model to understand.
- Grouping Operations: Method that uses Tidy. “Tidy datasets are easy to manipulate, model and visualize, and have a specific structure: each variable is a column, each observation is a row, and each type of observational unit is a table.” Three different ways to consolidate columns are through high frequency, pivot table, and one-hot encoding.
- Feature Split: An approach that splits a feature and at times makes it meaningful in ML. For example, a column that contains first name and last name can be split into two columns. One column represents the first name and second column last name.
- Scaling: A method that uses k-NN and k-Means calculation that can normalize data into fixed ranges using 0 and 1.
- Extracting Date: Approach that extracts dates and normalizes them, since dates can be presented in different ways such as 01/01/1985 or 1/1/85.
The nine techniques described above are specific to Emre Rencberoglu. Every data scientist has a method for feature engineering. Blogger Jason Brownlee looks at feature engineering differently. He defines feature engineering as follows:
“Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.”
In a blog post, Jason writes extensively on the topic of feature engineering, however, it goes beyond the scope of this discussion. Three interesting highlights that stood out are the following:
- Feature engineering is a representation problem, where ML must come up with a solution from the datasets
- Scores can be assigned to features. Features with higher scores can be used in a model and features with lower scores discarded
- Constructing the right features requires the user to spend a lot of time reviewing sample data and learning ways to expose the data to machine learning
In summary, feature engineering is the preparation of raw data that is to be used in the machine learning model. Data is usually represented in columns and rows. The columns are usually the features and creating the right features impacts the performance (accuracy) of the model. Four important factors in improving model accuracy are the features, data, model, and framing of the objectives.
Data cleansing is an important part of feature engineering. There are several tools and techniques available to help the data scientist with the process. After raw data is exported to a file, there are likely to be missing values in the columns. The nine techniques mentioned above identify the missing values, and depending on the use case, remove the row with the missing values. NumPy and pandas are Python libraries and tools that help with data cleansing. All it takes is a simple Python script, and the tool will clean up the data.