MLPerf is an “ML performance benchmarking effort with wide industry and academic support.” The organization behind MLPerf is MLCommons, an open engineering consortium whose mission is to “define, develop, and conduct MLPerf Training benchmarks” and create industry standards. The organization defines the rules, policies, and procedures for running unbiased benchmarks.
To date, there are 50 founding members that include companies like AMD, ARM, Cisco, Google, Alibaba, Intel, Facebook, Fujitsu, Microsoft, Samsung, NVIDIA, Red Hat, VMWare, and more. Peter Mattson, Google Staff Engineer and President of MLCommons gave a presentation at ScaledML Conference that provided the public with a wealth of information on MLPerf. He stated there are three types of MLPerf benchmarks.
- MLPerf Training: measures the time to train a model
- MLPerf Inference: measures the rate of inference
- MLPerf Mobile: measures the performance of inference on mobile devices
The MLPerf Training benchmark measures the time to train a model. Peter illustrated this point of view as “take a data set like ImageNet, run it through a model like Resnet, and set it to reach a target quality of a certain percentage.” Then measure how long it takes to do that. The beauty of the test is it measures real user value.

One of the questions that come up in benchmarking, should the model be specified. If it is specified, as in the above illustration, an apples-to-apples comparison can be done between different systems. If a model is not specified, engineers can use their own. The benefit of this approach, it leaves it open for anyone to use innovative methods to improve benchmarks. Perhaps the engineer invested heavily in creating a powerful algorithm or optimized the software stack or hardware to reach new levels of performance.
Closed Division and Open Division
The two different approaches mentioned above are called Closed Division and Open Division.
- Closed Division: Model is specified. Tends to be used by chip vendors
- Open Division: Model is not specified. Used by innovators and those who want to push the envelop by creating their own methods
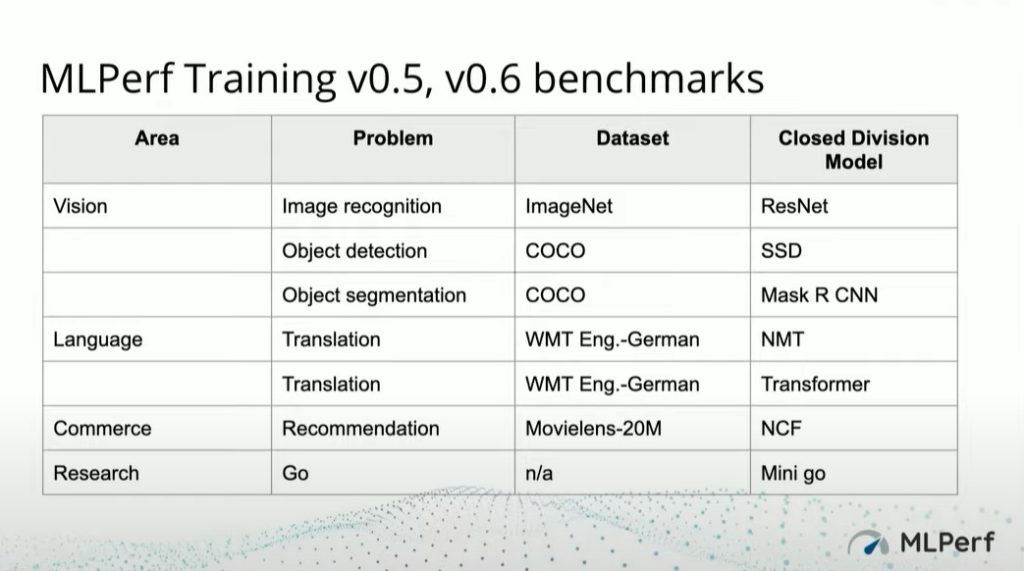
In MLPerf Training v0.5, v0.6 benchmarks, the consortium released seven different benchmarks in the areas of vision, language, commerce, and research, as illustrated below.
The MLPerf Inference benchmark measures the rate of inference. Peter explained it this way “take inputs, push them through a trained model, and make sure the model is performing at the right level of accuracy.” This approach is illustrated here:

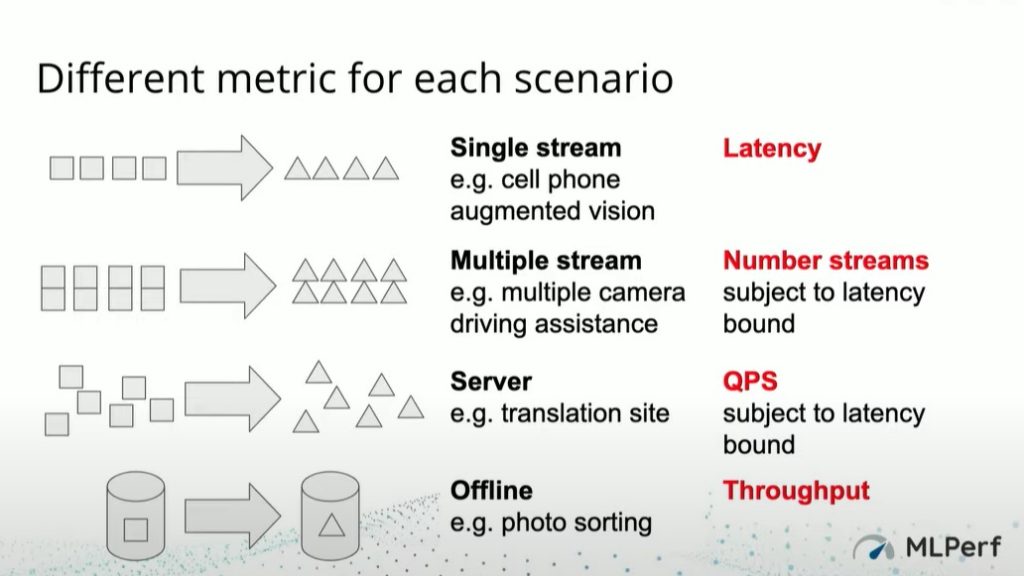
Inference tends to be used in more diverse situations. The consortium came up with four different scenarios.
- Single stream: steady stream of data arrives in order
- Multiple stream: several different streams arrive at the same time
- Server: data arrives in poisson distribution
- Offline: data arrives in chunks at certain times
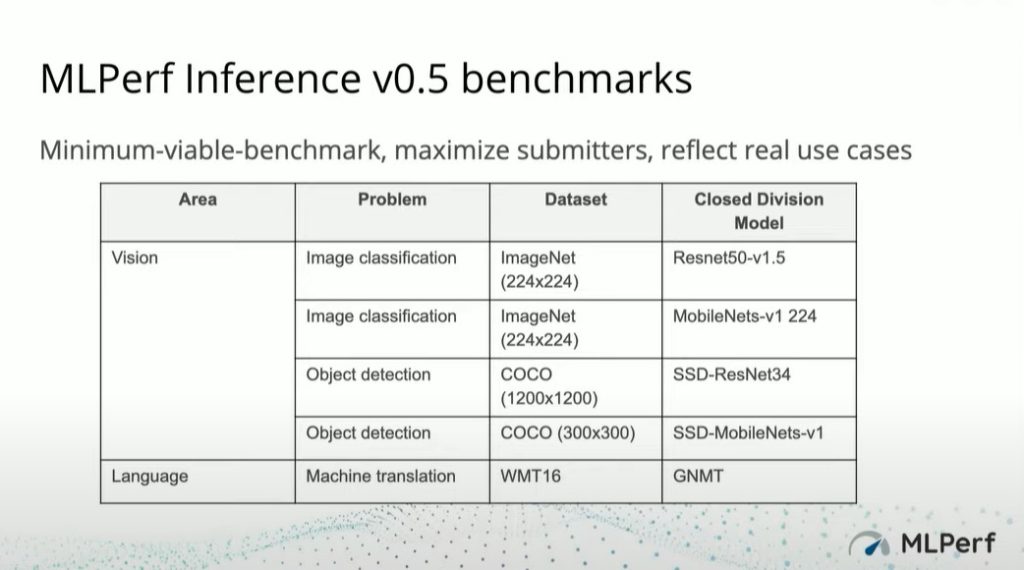
In terms of benchmarks, MLCommons created five benchmarks in the areas of vision and language, as illustrated here:
MLCommons is active and they are releasing updates on a regular basis. On June 30, 2021, the organization released MLPerf Training v1.0 which included two new benchmarks:
- Speech-to-Text with RNN-T: Uses speech input to predict corresponding text. Uses LibriSeech dataset.
- 3D Medical Imaging with 3D U-Net: Detects cancerous cells in kidneys. Uses KiTS 19 dataset.
In summary, MLCommons are developing benchmarks that are helping the global community measure and improve model performance.