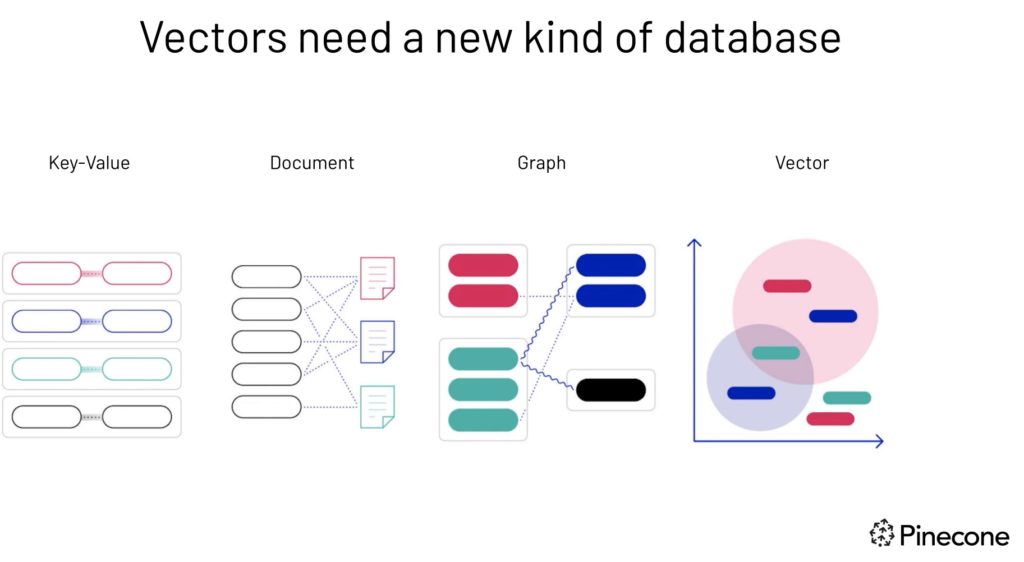
Vector databases are becoming increasingly important building blocks for machine learning. Traditional databases are not well suited for supporting machine learning because they were created decades ago to solve a different set of problems. This applies to SLQ and NoSQL databases.
SQL databases (DB) work with structured data, using features like primary keys, tables (rows and columns), and attributes to describe, store and organize data. One of the weaknesses of the SQL DB is its inability to scale horizontally to support increasing workloads. At the other end of the spectrum is the NoSQL database. They work with semi-structured and unstructured data and come in the form of the document store, key-value store, graph database, and column-oriented DB. One of the main benefits of the NoSQL DB is its ability to scale horizontally, supporting any volume of workload.
Although SQL and NoSQL databases might work for some ML use cases, vector databases are better suited for use cases involving text, search, recommendation, audio, and NLP.
What is a Vector Database
The vector database stores data such as text, image, and audio in the form of vectors. A vector is a list of numbers represented as a sequence of numbers or as a single value in a row and a single value in the column section, as illustrated below.
- Scalar: has magnitude such as distance, speed, time, temperature, and area
- Vector: has magnitude and direction such as velocity, momentum, and acceleration
- Matrix: table of numbers representing rows and columns

Vector databases differ from traditional databases because data isn’t stored in tables or as documents but as numeric values along an x and y-axis represented as a sequence of numbers as shown below.

Each data type, whether it’s an image, audio, or text must be transformed. For example, in NLP, a transformer like GPT-3 is used to transform data from one format to another. Breaking it down further, there is a process called word embedding that assigns a unique numeric value to a word.
Vector Databases
The vector database industry is growing. Presently, there are a few open-source products on the market. And there are commercial products available like Pinecone. Some of these products have been developed from the ground up to support the unique data requirements of machine learning.
Milvus
Milvus is one of the most most popular open-source vector databases that can manage trillions of vector datasets. It’s widely used in applications like new drug discovery, autonomous driving, chatbots, computer vision, and recommendation engines.
Features
- Millisecond search on trillion vector datasets
- Simplified unstructured data management
- Reliable, always on vector database
- Component-level scalability and elasticity make resource scheduling more efficient
- Facilitates hybrid search over data types such as integers, Boolean, floating-point numbers, and more
- A unified lambda structure makes batch processing timeless and efficient
- Excellent community support with more than 1,000 enterprise users, 8,000+ stars on GitHub
Weaviate
Weaviate is a Go-based low-latency vector search engine and vector database. It leverages ML to vectorize and store data and to answer natural language queries. The platform provides exceptional support for different media types, such as images, and text. It also facilitates semantic search, customizable models, question-answer extraction, classification, and more. Since it stores both objects and vectors, users can combine vector search and structured filtering with the tolerance of a cloud-native database. It’s accessible via REST, GraphQL, and other language clients.
Features
- Fast queries. It can perform a ten nearest neighbor (NN) search out of millions of objects in less than 100ms
- Supports any media type
- Combines scalar and vector search
- Can process real-time data, and writes are performed to a Write-Ahead-Log (WAL) for immediately persisted writes
- Scale Weaviate as per your needs – large datasets, maximum ingestion, high-availability
- Cost-effective. Large datasets don’t occupy memory, and memory can be used to increase the queries’ speed.
- Makes arbitrary graph-like connections between objects
Vespa
Vespa is a feature-packed text search engine that fully supports traditional information retrieval and modern embedding-based techniques. Besides, it’s extensively used for recommendation and personalization, question answering, and semi-structured navigation.
Features
- Fast nearest neighbor search (ANN) in vector spaces
- Matching by structured metadata
- Combining matching operators in the same query by AND and OR
- Facilitates 2-phase ranking
- Ranking by arbitrary mathematical expressions over tensor and scalar features
- Grouping, aggregation, and deduplication overall matches
Vald
Vald is a fully scalable and open-source distributed fast ANN dense vector search engine. It runs on the cloud-native architecture and uses the fastest ANN algorithm NGT to search neighbors. The search engine facilitates automatic vector indexing and index backup and horizontal scaling for searching from billions of vector data. You can customize it based on your unique needs.
Features
- Asynchronous Auto Indexing
- Customizable Ingress/Egress Filtering
- Cloud-native based vector searching engine
- Auto Indexing Backup
- Distributed Indexing
- Index Replication
- Ease to use
- Highly customizable
- Multi-language supported
Pinecone
Pinecone is a commercial, fully managed vector database designed to ease adding vector search to production applications. The product combines vector search libraries, functions such as filtering, and distributed infrastructure. Most of all, it provides high-performance search regardless of scale.
Features
- Search from billions of vectors in tens of milliseconds
- Operates on secure GCP or AWS environments in multiple regions
- Facilitates semantic search and unstructured data search
- Used for duplication and record matching, recommendations, ranking, detection, and classification
Kinetica
Kinetica is a commercial vector database that natively supports vectorization on GPUs and CPUs. It’s basically a memory-first platform featuring tiered storage that uses vectorization to parallelize tasks at instruction levels. It has an integrated analytical suite of tools that helps deliver real-time analytics and high-speed streaming.
Features
- Sequential processing
- Task-level parallel processing
- Data-level parallel processing (Vectorization)
- Machine learning
- Graph analytics
- IoT analytics
- Real-time analytics
- Supply chain optimization