How PrestoDB and Trino can help you to manage distributed SQL Databases? First, it is important to remember that a distributed SQL Database is formed by multiple databases, each of which contain a subset of the data, that work together as one. This way, you can add performance or storage capacity by adding more database instances. The software engine behind this has the task to guarantee data consistency and is the one that other softwares would communicate with, instead of each of the separated database instances.
In this blog post, we are going to explain more about PrestoDB and Trino origins, how they work and their main features.
PrestoDB’s Origin and Main Features
PrestoDB was developed by Facebook back in 2013 as a solution to query their massive database. Existing technology at the time wasn’t ready to query such large amounts of data, or query several data sources at the same time. These were the challenges that needed to be solved, and to do it quickly. Low latency was a must too. For this reason, Facebook developers insisted on building it as an open source software, so others could benefit from the distributed SQL idea.
At Facebook, PrestoDB powers some of their analytic tools, supports interactive/BI queries and long-running batch extract-transform-load (ETL) jobs, and serves high performance dashboards. Besides that, it provides an SQL interface to other internal NoSQL systems, and also supports Facebook’s A/B testing infrastructure. PrestoDB processes hundreds of petabytes of data for the company everyday.
Other use cases are ad-hoc querying, allowing you to query data wherever it’s stored, or query your data directly from a data lake, without the need to transform it. Answers are aggregated when querying different databases, data lake or cloud lake houses at the same time. Finally, PrestoDB is compatible with most of the more popular data source options such as: AWS S3, Alluxio, Cassandra, Hadoop, Kafka, MongoDB, MySQL and Teradata.
Any business that deploys PrestoDB can perform (and benefit from) any of the tasks mentioned above, having their different data sources in multiple data centers. All done in an efficient, scalable and flexible way.
Trino Emerged as a Broader Solution
Between late 2018 and the start of 2019, an important group of PrestoDB developers left the project and formed Trino (known as PrestoSQL until 2020). It was a fork of PrestoDB, but the idea was to expand the tool’s use cases. Even though PrestoDB and Trino share 6 years of history, since the split, Trino has continually gained more popularity, adoption and developers contributing to the project, compared to the original PrestoDB.
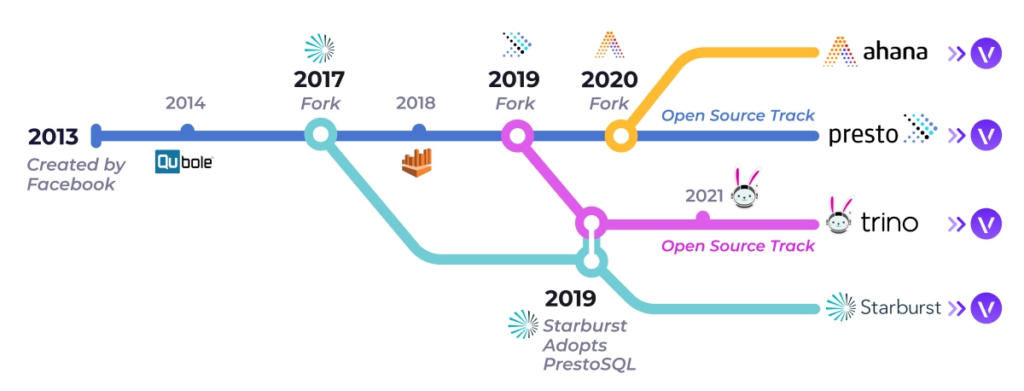
Trino was designed to query large amounts of data distributing queries in several instances. Its connectors enable Trino to interface directly with cloud computing stacks. It can handle several relational databases and can be upgraded to create visual interfaces. This way, Trino helps to improve performance and enable users to complete their tasks, saving effort and resources.
According to the project’s website, “Trino was designed to handle data warehousing and analytics: data analysis, aggregating large amounts of data and producing reports. These workloads are often classified as Online Analytical Processing (OLAP).”
PrestoDB is focused on big data businesses similar to Facebook. Differently, Trino has become much more than that by broadening itself to become a comprehensive SQL querying engine, with better capabilities and more suitable for companies with different data situations.
Trino is being updated several times each month. Granular fault tolerance implementation, migration to Java 17 as base for Trino’s code, or updates to connectors used to communicate with different databases are just some examples of the constant development done to this product by developers and community members.
Real Life Use Cases for PrestoDB and Trino
We already talked about Facebook’s gigantic database being continuously queried and processed by PrestoDB. Both Presto and Trino are the most adopted distributed SQL Engines and have been proven to work in several big companies, such as Netflix, Airbnb, Twitter, Comcast, Uber, and many more.
For example, Robinhood uses Trino for data analysis, business intelligence and to have visibility of its global platform to help with availability and performance issues. The company also uses several Trino clusters connected to different data sources, allowing business users to query them at will.
DoorDash uses Trino to enable queries on its data architecture. Similar to Robinhood’s structure, this allows internal users to run data analytics on business processes and operations.
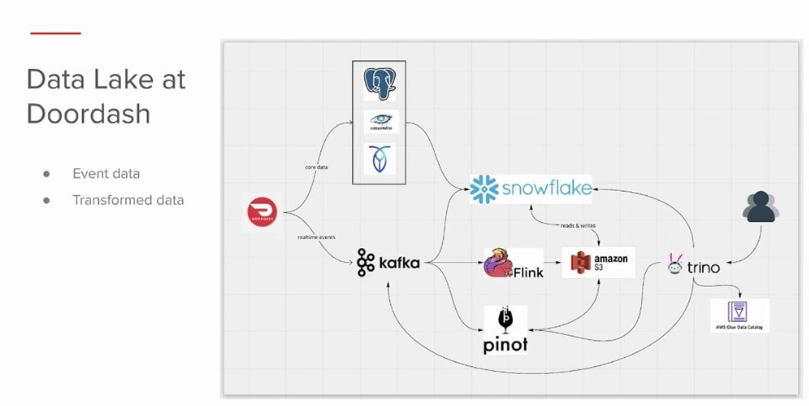
LinkedIn and Electronic Arts are other companies that have adopted Trino for their business needs.
Summary
Big Data architectures continue to evolve rapidly. Engaged communities are needed to keep up and adapt products to new paradigms, trends and continuously keep improving. In this context, it seems both PrestoDB and Trino will keep leading the way as the prime Open Source projects focused on harvesting the power of Distributed SQL Engines.