Kubeflow is a workflow platform developed by Google to help developers deploy and manage Machine Learning (ML) workflows on Kubernetes (K8s).
From a broader context, Machine Learning does not just complain about building, training, and deploying. These are part of a set of workflow steps that includes data collection and validation, monitoring, and the inclusion of analysis tools, choice of service infrastructure, configuration, pattern extraction, use of process management software, and the management of computing resources.
For this reason, ML workflow operations become complex and time-consuming, often involving different teams and numerous stages. Tools like Kubeflow aim to simplify and streamline these workflows by providing an integrated platform for managing the entire process.
This post will review the main stages of ML modeling and how the Kubeflow approach makes it all easier.
Background: Kubernetes Enables MLOps
Machine Learning Process
Machine learning is a subset of the Artificial Intelligence (AI) field for studying and building “learning” models, which involves the development of advanced algorithms. These algorithms are commonly based on strategies (Artificial Neural Networks, Decision Trees, Regression Analysis, Bayesian Networks, Genetic Algorithms, and more), statistical models, and inferences. Despite significant advances in recent years, this field still has its challenges.
For example, during the first steps of ML modeling, data scientists and engineers may consider conducting extensive ML experiments precisely and in a reproducible way. They also may want the freedom of running specific ML workflows on-premises and others utilizing cloud services to facilitate the deploying and scaling and enable the parallelling of multiple tasks. Therefore, these professionals, despite their broad level of knowledge, must go a step further, using new technologies and dedicated tools for this purpose.
Regardless of the number of experiments, model type, and the environment in which they are run, a standard ML process can be divided into the following fundamental stages:
- Analyzing the Problem:An ML model usually starts with the problem analysis before creating the code. It could consist of understanding the problem statement, gathering, preparing, cleaning, and exploring data to gain insights and determine the best approach (ML model) to solve the problem.
- Writing Code and Lab Evaluation: It consists of selecting and writing the appropriate algorithm, and evaluating the model for a not-so-large amount of data. It is more considered a laboratory stage.
- Fine-Tuning the Model’s Parameters: Engineers must evaluate the ML model’s performance using metrics such as error, efficiency, accuracy, or precision. In addition, they could apply an iterative optimization process to optimize coefficients or weighting factors of the model.
- Deploying and Managing: Once the model has been approved according to the highest accuracy requirements, the last step of a data scientist is to deploy the model in a production environment. It could enclose handling large amounts of data, monitoring the ML model performance, making necessary adjustments to the model coefficients, retraining, and more.
Certainly, this is not the golden rule, but it serves the purpose of this post. It is necessary to understand that the ML process follows these basic steps and more, so we can hope that specific approaches can vary from case to case. However, as any ML code evolves, it demands more computational resources, large environments like a cloud, and specialized tools to manage them effectively. Here is where Kubernetes plays an important role.
Kubernetes
Kubernetes is an open-source container orchestration software for automating the management of containerized applications. It provides a platform-agnostic way to containerize applications by abstracting away the underlying infrastructure and providing a consistent set of APIs. It enables users to define the desired state of their applications in a declarative manner using configuration files called manifests. These manifests specify all aspects of an application’s lifecycle, such as storage requirements, networking configurations, load balancing strategies, health checks, and update policies.
Kubernetes provides several benefits for ML deployments, including:
- Scalability: It automatically scales the workload to match the demand, whether K8s handles larger data sets or uses multiple machines to perform distributed training.
- Isolation: Containers provide a high isolation level which is beneficial when running tasks with sensitive data.
- Monitoring and Observability: Users can employ monitoring features to inspect the status and performance of ML workflows.
- Portability: It allows users to deploy ML models on-premises, on the cloud, or in a hybrid environment, making it a flexible option for different scenarios.
However, everything is not bright, and problems and challenges still exist to overcome. Kubernetes can’t perform all the steps that ML workflows require. In addition, deploying ML workflows into the Kubernetes platform can be problematic because it often involves a combination of different tools and libraries with specific dependencies and requirements. That’s why Google created the Kubeflow project and its complete set of tools.
Deploying and Managing with Kubeflow
Kubeflow is an open-source platform that simplifies and automates ML workflows on Kubernetes. It allows engineers to manage and customize multiple ML models and define pipelines as multi-stage processes, including data preparation, training, and tuning.
Kubeflow is well recognized as an easy-to-use tool since it provides intuitive components and tools like Kubeflow Notebooks, Training Operators, Model Serving, Katib, and more.
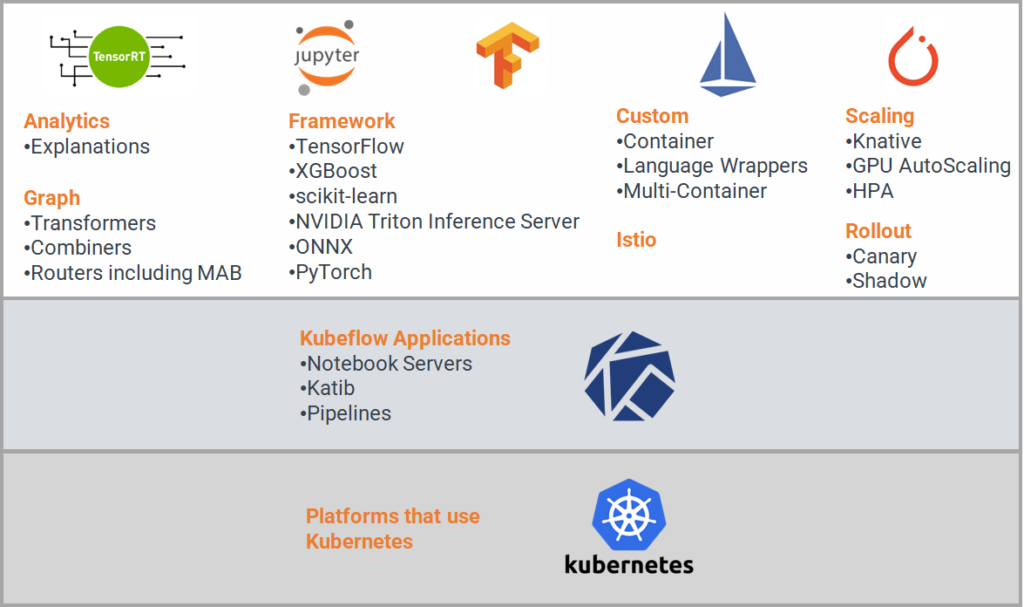
Components
Kubeflow Notebooks
Kubeflow enables the integration of JupyterHub, a tool that facilitates the use of web-based IDEs within a Kubernetes cluster by running them in Pods. It gives users native support for Visual Studio Code, JupyterLab, and RStudio, and allows the creation of notebook containers directly in clusters.
Kubeflow Pipelines
Pipelines is a tool for deploying and building end-to-end ML workflows and provides a user-friendly interface for managing pipelines. Kubeflow Pipelines is a scheduling engine for multi-step workflows that allows users to easily chain together different steps of an ML pipeline, such as data preprocessing, training, and serving. It also supports the use of Docker containers, which makes it easy to package and deploy in a portable and consistent way.
Katib
Katib is a Kubernetes-based tool for Automated Machine Learning (AutoML) that includes features such as hyperparameter tuning, early stopping, and Neural Architecture Search (NAS). It is compatible with multiple frameworks and offers a wide range of AutoML algorithms, including Bayesian Optimization, Tree of Parzen Estimators, Random Search, Differentiable Architecture Search, and more. Currently, it is in the beta version.
Training Operators
Kubeflow Training Operators is a set of Kubernetes custom resources (TFJob, PaddleJob, PyTorchJob, and more) that provides a way to automate the deployment and scaling of ML training workflows.
Model Serving
Kubeflow offers two model service systems, KFServing and Seldon Core, each equipped with a comprehensive set of features and sub-features to meet the diverse needs of engineers. These features include support for different ML frameworks, graphing, analytics, scaling, custom servicing, and integration with Istio for universal traffic management, telemetry, and security for complex deployments.
In sum
Kubeflow is an open-source Kubernetes native workflow engine for deploying complex ML workflows. This tool is one among many in the open-source ecosystem using ML models (See Argo Workflow post).
Kubeflow began life within Google, designed to run TensorFlow jobs but grew to support multi-cloud and multi-architecture frameworks. Companies like IBM, Red Hat, Cisco, and other large tech companies contribute to this project today. And it supports a wide array of projects like TensorFlow, PyTorch, Chainer, MXNet, Ambassador, XGBoost, Istio, Nuclio, and more.