You probably have observed that a typical search result on Google, Bing, or Yahoo takes less than a second to display on your screen. For this to happen, the search engine of your web browser must be previously informed of both new and old content so that it is readily available when required. Developers design these search engines with a set of components such as crawlers, indexing, ranking, and solvers to provide fast responses.
Search engines use these components (algorithms) to find, classify, and deliver the best web pages, documents, images, and other types of content, making it easy for users to search through a large number of resources available on the Internet. In addition, these engines must have the capability of providing categorized results with relevant content.
The search engines are not limited exclusively to big and well-known web browsers. Companies worldwide and even professionals of different sectors can create search engines for different applications like scraping purposes which consist of downloading data from web pages such as articles, job offers, clothes, and accessories from hundreds of news sites.
If you want to know more about search engines, this post presents information about their main components and how you can start working with web scraping by using an open-source tool.
Web Crawler or Web Scraping?
Although they have similar algorithms, web crawling, and web scraping are two different techniques for gathering data from the Internet.
Web Crawler
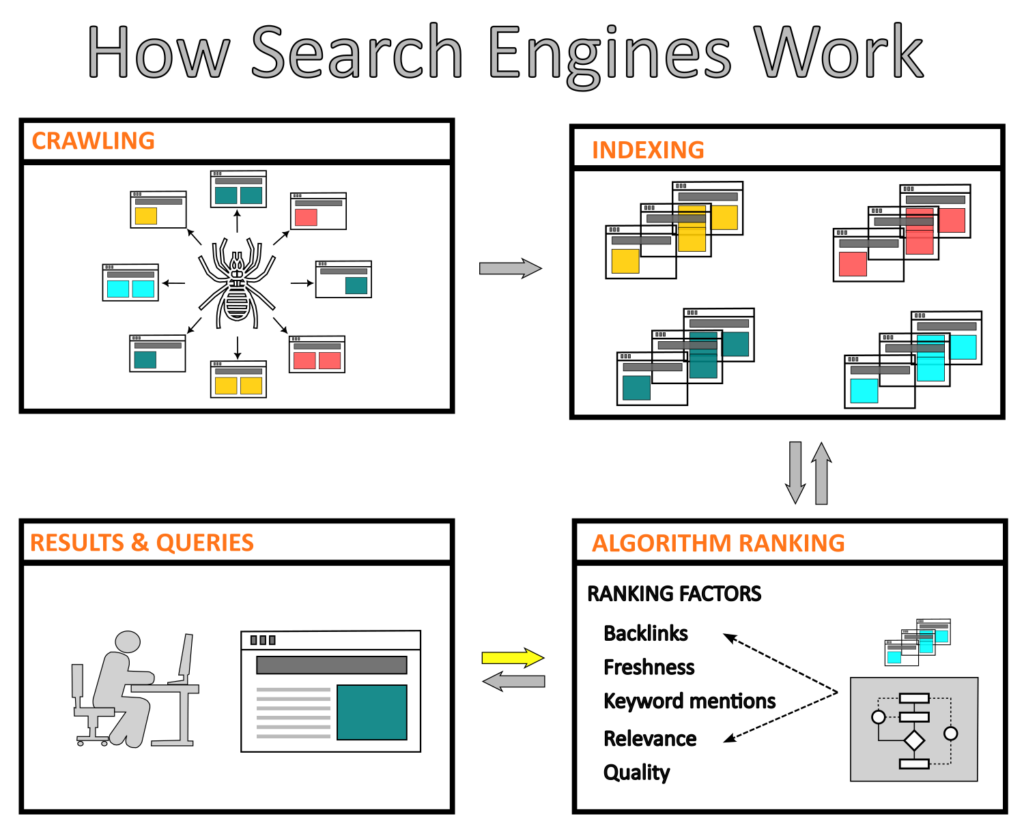
A web crawler is an algorithm, called as bot or spider, that scours the internet, inspecting it methodically and automatedly. It analyzes a website to gather specific content and create entries that will be used by the search engine’s index.
The crawling process begins with a list of URLs to be visited. Then, the crawler downloads and parses the content to extract information such as links, HTML, CSS, or JavaScript files in the form of items. Finally, it processes these items by employing cleanup, validation, and persistence tasks.
Since thousands of new web pages are created every day, the crawler must go through this process over and over again, adding new and updated pages to its list of known URLs.
Overall, web crawling is an essential process of a search engine in which algorithms systematically scour and download specific content from the Internet. This content is only used to index and classify web pages.
Web Scraping
On the other hand, web scraping is the process of downloading content from web pages. In other words, Users can work on any site by identifying and extracting the data. Web scraping can be used for a wide range of applications, such as:
Research: Searching and downloading data is the first step of any researcher in a project, whether purely academic or for marketing, financial, or other business goals.
Retail / eCommerce: Companies must regularly perform market analyses to maintain competitiveness. For example, they must always be aware of pricing, or special offers to stay one step ahead of their competitors.
Cyber security: Content creation is increasingly becoming an integral part of businesses. Although most of this content is public, like product prices on Amazon or research data in a post, personal data, and intellectual property are exposed to cyberattacks from actors who illegally benefit from it. Collecting data allows authors to monitor and protect their sensitive data.
Overall, web scraping helps users systematically and automatically extract specific data from a website and make it available for different purposes.
Web Indexing
Indexing websites’ content involves collecting, categorizing, and storing information from web pages to create an easily searchable database. By indexing content, search engines can quickly retrieve and provide the results of a user’s query.
Here’s a clear and concise explanation of it:
“Once we have these pages (…) we need to understand them. We need to figure out what is this content about and what purpose does it serve. So then that’s the second stage, which is indexing.” – Martin Splitt, WebMaster Trends Analyst, Google
Search Engine Ranking
When the search engine receives a user’s query, it must have the capability of displaying results according to assessment criteria. It is done by a complex algorithm the search engine uses to compare keywords and phrases between the query and the indexed content and then rank the results based on ranking factors.
For example, the ranking factors of Googlebot in no particular order are relevance, quality, usability, location, and more.
Improving Websites Ranking with SEO Strategies
Sometimes search engines are unable to crawl a new web page, which can prevent it from being indexed and displayed in search results. This can be caused by several factors, such as errors in the robots.txt file, server connectivity issues, website design issues, or content issues. Although new pages may take some time to be crawled and indexed by search engines, if they are correctly optimized and technical issues fixed, they can improve their visibility and ranking in search results.
For this reason, trained professionals use SEO techniques to optimize content according to specific strategies that can facilitate indexing.
Use the following tips to improve the ranking of your content:
- Use short URLs
- Add novel content
- Create a title with a short number of characters
- Insert an image related to the topic
- Create paragraphs with no more than 300 words
- If you are writing a post, mention 1-3 people
- Define a keyword, use it in the title, and maintain its density throughout the text.
An Open-Source Framework for Web Scraping
Web scraping is becoming increasingly popular for extracting data from websites for further analysis. To perform web scraping, you must have basic knowledge of HTML and CSS, as it will allow you to understand the structure of a web page. You should also know how to use a tool like Scrapy to create your algorithm to extract data automatically.
Note: it is important to consider that data extraction must be legal and ethical; otherwise, it can lead to sanctions. Check the DMCA (Digital Millennium Copyright Act) law for more information.
Scrapy is an open-source Python-based web crawling platform that allows users to extract data from websites. It was created initially for web scraping but is also used as a general-purpose web crawler. Scrapy is based on “spiders,” which are classes that define the technique for extracting data from a particular site. It is currently maintained by Zyte, a large company specializing in web crawling.
“Scrapy is really pleasant to work with. It hides most of the complexity of web crawling, letting you focus on the primary work of data extraction.” –Jacob Perkins, author of Python 3 Text Processing with NLTK 3 Cookbook.
To use Scrapy, install a Python IDE on your machine and run the command in the terminal: “pip install scrapy.” Using an Anaconda distribution, you must run the command: “conda install -c conda-forge scrapy.”