Apache Hive
I. Introduction
Product Name: Apache Hive
Brief Description: Apache Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. It enables analysts and developers to write SQL-like queries against a variety of data sources residing in Hadoop.
II. Project Background
- Library/Framework: Apache Software Foundation
- Authors: Facebook (original creators)
- Initial Release: 2007
- Type: Data warehouse infrastructure
- License: Apache License 2.0
III. Features & Functionality
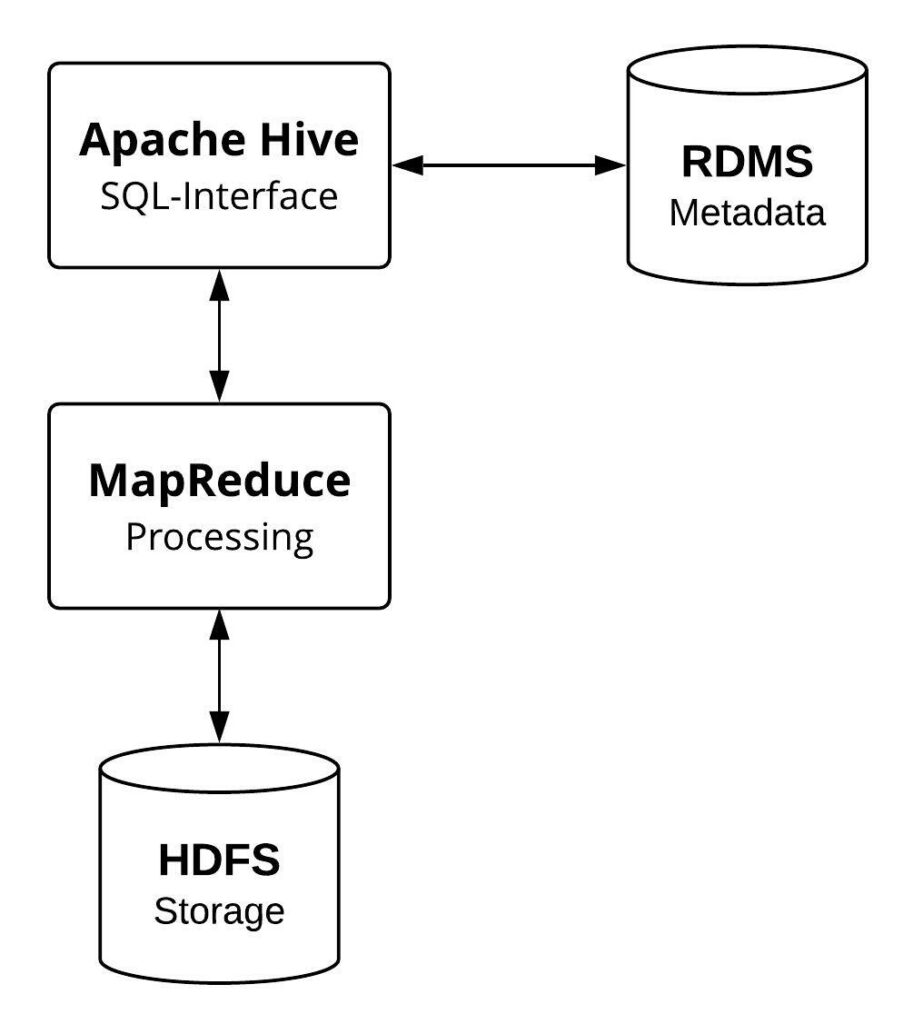
- SQL-like Interface: Provides a familiar SQL-like language (HiveQL) for querying data.
- Data Warehousing: Enables data summarization, analysis, and querying on large datasets.
- Schema on Read: Defines data schema at query time, providing flexibility.
- Integration with Hadoop: Leverages HDFS for storage and MapReduce/Tez/Spark for processing.
- Data Formats: Supports various data formats (Parquet, Avro, ORC, etc.).
- Metadata Management: Stores data metadata in the Hive Metastore.
IV. Benefits
- Ease of Use: Provides a SQL-like interface for non-programmers.
- Scalability: Handles large datasets and complex queries.
- Flexibility: Supports various data formats and query engines.
- Cost-Effectiveness: Leverages Hadoop infrastructure.
- Integration: Works seamlessly with other Hadoop ecosystem components.
V. Use Cases
- Data Warehousing: Creating and managing data warehouses.
- ETL Processes: Loading and transforming data into a data warehouse.
- Data Analysis: Querying and analyzing large datasets.
- Reporting: Generating reports and visualizations.
VI. Applications
- Financial services
- Telecommunications
- Retail
- Government
- Scientific research
VII. Getting Started
- Set up a Hadoop cluster.
- Install Apache Hive.
- Create databases and tables.
- Load data into Hive tables.
- Write HiveQL queries to analyze data.
VIII. Community
- Apache Hive Website: https://hive.apache.org/
- Apache Hive Mailing Lists: [Link to mailing lists]
- Apache Hive GitHub: https://github.com/apache/hive
IX. Additional Information
- Tight integration with Hadoop ecosystem.
- Supports various query engines (MapReduce, Tez, Spark).
- Active community and ecosystem of tools and libraries.
X. Conclusion
Apache Hive is a popular data warehousing solution for Hadoop. It provides a SQL-like interface for querying and analyzing large datasets, making it accessible to a wide range of users.