Scrapy
Scrapy is an open-source Python-based web crawling platform that allows users to extract data from websites. It was created initially for web scraping but is also used as a general-purpose web crawler. Scrapy is based on “spiders,” which are classes oriented to define the methodology for crawling and extracting data from a particular site. It is currently maintained by Zyte, a large company specializing in web crawling.
The Scrapy package can be used across sectors for several purposes, including data mining, monitoring, analyzing, and testing. It allows developers to reuse their code, making it easier to construct and grow huge crawling applications. In addition, Scrapy comes with a web-crawling shell that developers may use to test their assumptions about a site’s behavior.
Components
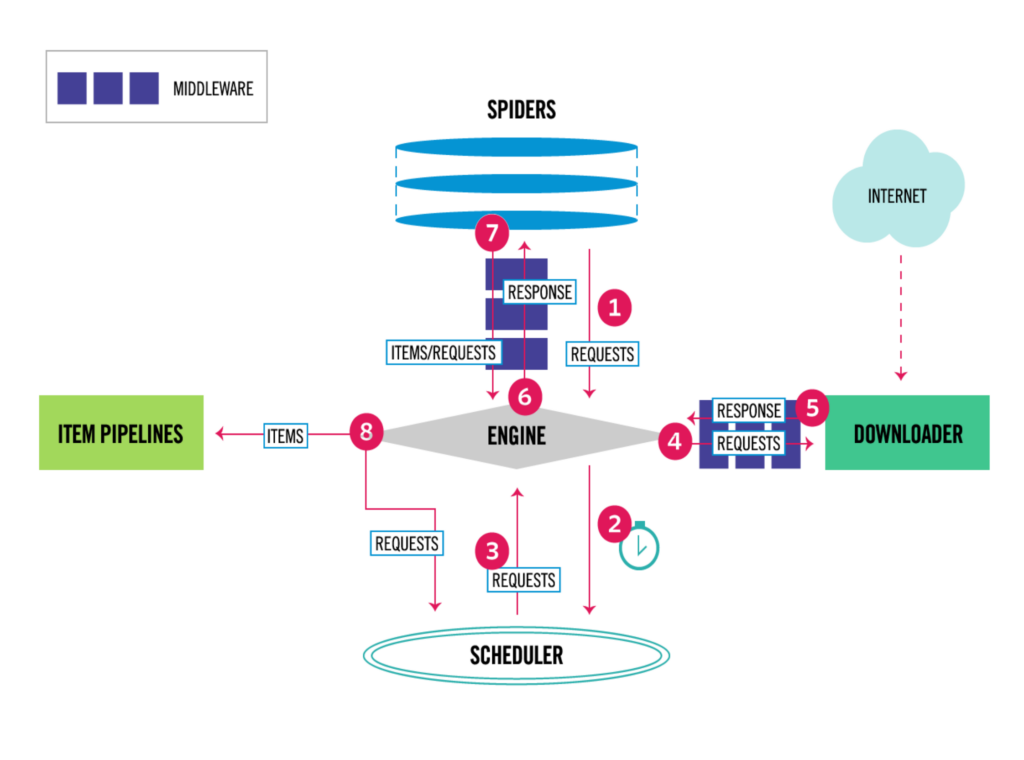
Scrapy Engine
The Scrapy engine is the central component of the workflow operation since it manages the data flow among all the system components, generating events when specific actions occur.
Scheduler
This component is responsible for scheduling and receiving “requests” from the engine, generating queued requests to be returned to the engine.
Downloader
The role of the Downloader is to scour the Internet for content (web pages) and deliver it to the Scrapy engine. Subsequently, the engine will send the info to the next component (also called spiders).
Spiders
Scrapy uses custom classes (also called Spiders) to analyze “responses” and extract data (as items) from unstructured sources, typically web pages. Users must be sure that their code receives any item type since Spiders supports multiple types of it.
To accomplish this, Scrapy provides multiple functions via “itemadapter” library to support the different item types, including dictionaries, item objects, dataclass objects, and attrs objects.
Item Pipeline
Once the spiders have scraped the items, the Item Pipeline is responsible for processing them. It involves tasks like cleansing, validation, and persistence, which may include storing the items in a database.
Downloader middlewares
Downloader middlewares is a Scrapy component that allows for customizable processing of requests and responses that come and go from the downloader. Its main uses are:
- process a request before reaching the site;
- modify a response or avoid sending it to the spiders by generating a new request, and
- send a response to the spiders without having scoured the internet for content;
Spider middlewares
These middlewares can be used to modify requests and responses that come and go from the spiders. It provides a way to customize the behavior of spiders, such as:
- post-process output of spider callbacks;
- post-process start_requests, and
- handle spider exceptions.
Scrapy vs. Python Libraries for Web Scraping
These Python libraries were initially developed for distinct purposes but are also used for web scraping tasks. Scrapy is ideal for web crawling, while Selenium is designed to automate website interaction and scrape dynamic websites. Beautiful Soup is mainly used for parsing HTML and XML documents and extracting data from web pages.
| Scrapy | Selenium | Beautiful Soup | |
| License | BSD License | Apache Software Foundation | MIT license |
| Purpose | Data mining, monitoring, and automated testing. | Mainly for web browser interaction. It is also used with tasks related to web scraping. | Parsing documents. |
| Description | Scrapy is a Python-based web crawling platform that is free and open-source. It was created with web scraping in mind. | Selenium is a Python package used typically to automate web browser interaction. | Beautiful Soup is a Python library specializing in parsing HTML and XML documents to generate a parse tree. This parse tree can then be leveraged to extract data from the HTML code. |
| Performance | Fast because of its asynchronous system calls. | Used for simple scraping jobs with efficiency. | Used for simple scraping jobs with efficiency. |
| Supported data | The extracted data is provided in CSV, XML, and JSON formats. | It can handle data that can be accessed through a web browser and data that is loaded dynamically via AJAX requests. | It can parse HTML and XML documents. |
| Components/Modules | Engine, Scheduler, Downloader, Spiders, Item Pipeline, Downloader middlewares, and Spider middlewares. | Web driver, API, and Libraries. | Parser, Tag object, and NavigableString object. |
| Cons. | It is not well-suited for scraping websites with dynamic content. | Users need to install a WebDriver component in the working browser. | It requires additional packages (e.g., requests and urlib2) to open URLs and retrieve the data. |
Sources: Scrapy, Selenium, and Beautiful Soup.
Quick Installation Guide
Python 3.0 (and onwards) already has Scrapy installed. For conda users, use the following command in the Anaconda prompt to verify that it is in your system.
conda list
It will print a list, and you will be able to see the “scrapy” package. If your system does not contain Scrapy, you can install it by running the command:
conda install -c conda-forge scrapy
Look at these tutorials to install Anaconda for Windows and Ubuntu. Alternatively, you can use the pip package manager.
pip install scrapy
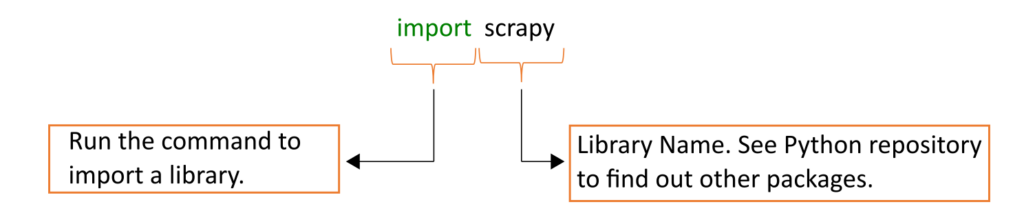
Once the installation is complete, you can import the package into your code.
import scrapy
Highlights
Project Background
- Project: Scrapy
- Author: Zyte
- Initial Release: 2008
- Type: Web Crawler
- License: BSD License
- Contains: web crawling shell
- Language: Python
- GitHub: /scrapy
- Runs On: Windows, Linux, MacOS
- Twitter: /scrapyproject
Main Features
- Data mining, monitoring, and automated testing.
- Open-source Python-based web crawling platform.
- It lets users focus on essential tasks of data extraction.
- It simplifies the complexity of web crawling.
Prior Knowledge Requirements
- Users should have a basic understanding of the Python programming language.
- Familiarity with HTML and CSS.
- USers should know XPath and CSS selectors to locate and extract data from web pages.
Projects and Organizations Using Scrapy
- Zite: (formerly Scrapinghub) is currently the largest company sponsoring Scrapy development. It specializes in web crawling, it was founded by Scrapy creators and employs crawling experts including many Scrapy core developers.
- ScrapeOps: is a DevOps tool for web scraping, which provides a suite of monitoring, error tracking, alerting, scheduling and deployment tools for your Scrapy projects when you install the scrapeops-scrapy extension. ScrapeOps also publishes Scrapy guides & tutorials at The Scrapy Playbook.
- Arbisoft: scours massive websites several layers deep to collect valuable data powering leading firms around the world. It offers realtime crawling and custom-built fully-managed spiders. Over 6 years of quality service, their Python engineers have come to trust Scrapy as their tool of choice.
- Intoli: uses Scrapy to provide customized web scraping solutions, delivering data that is used by clients to power their core products, for lead generation, and for competitor research. They specialize in advanced services such as cross-site data aggregation, user logins, and bypassing captchas.
- Source: /companies/
Community Benchmarks
- 46,300 Stars
- 9,900 Forks
- 500+ Code contributors
- 30+ releases
- Source: GitHub
Releases
- 2.8.0 (2-2023): This is a maintenance release, with minor features, bug fixes, and cleanups.
- 2.7.1 (11-2-2022): Update and Fixes, e.g., Relaxed the restriction introduced in 2.6.2.
- 2.7.0 (10-17-2022): Update and Fixes, e.g., Added Python 3.11 support, dropped Python 3.6 support.
- 2.6.3 (9-27-2022): Update and Fixes, e.g., Makes pip install Scrapy work again.
- 2.6.2 (7-25-2022): Update and Fixes, e.g., Fixes a security issue around HTTP proxy usage.
- Source: Releases