ONNX Runtime
ONNX Runtime (ORT) is a comprehensive open-source ecosystem that accelerates the performance of Machine Learning (ML) models by providing a standardized file format and a set of operators, which allows interoperability among various dedicated ML frameworks, such as TFLite, PyTorch, Tensorflow/Keras, scikit-learn and others. By supporting a broad range of programming languages and platforms, ONNX Runtime enables efficient and optimized deployment of ML models on diverse devices, such as CPUs, GPUs, and mobile devices.
Using ONNX Runtime, developers can easily switch between different frameworks for specific stages of the development process, including rapid training, flexible network architecture, and inferencing. This flexibility allows developers to choose the most appropriate framework for their specific use case and integrate it with the rest of their ML pipeline. The standardization provided by ONNX Runtime helps to reduce the complexity of the ML development process and ensures that ML models can be easily ported across different environments.
Fundamentals
ORT for Inference
At the most general level and not from a statistician’s point of view, inference refers to the process of applying a trained machine learning model to new input data to make predictions or decisions. The input data is fed into the model, and the model uses its learned parameters and algorithms to generate an output that represents the predicted outcome for that input. This output can take many forms, depending on the type of model and the nature of the problem being solved.
Inference is a critical step in the machine learning workflow, as it enables models to be used in real-world applications to make decisions or provide insights. ONNX Runtime offers a performance boost to the inference process by leveraging Execution Providers (EPs), which are hardware-specific optimization modules designed for various types of hardware, such as CPUs, GPUs, and FPGAs. Some use cases include:
- Enhance inference in ML models.
- Run on different hardware and OS configurations.
- Train models using Python and deploy them into a C#, C++, or Java App.
- Train and execute models created in different frameworks.
Hardware Acceleration
ONNX Runtime supports hardware acceleration through Execution Providers, which enable developers to optimize the execution of their ONNX models by leveraging the specific compute capabilities of the hardware platform. It offers a flexible and extensible architecture, allowing developers to deploy their ONNX models in different environments, including on-premises, cloud, and edge devices, and take advantage of the available hardware resources to accelerate the model inference.
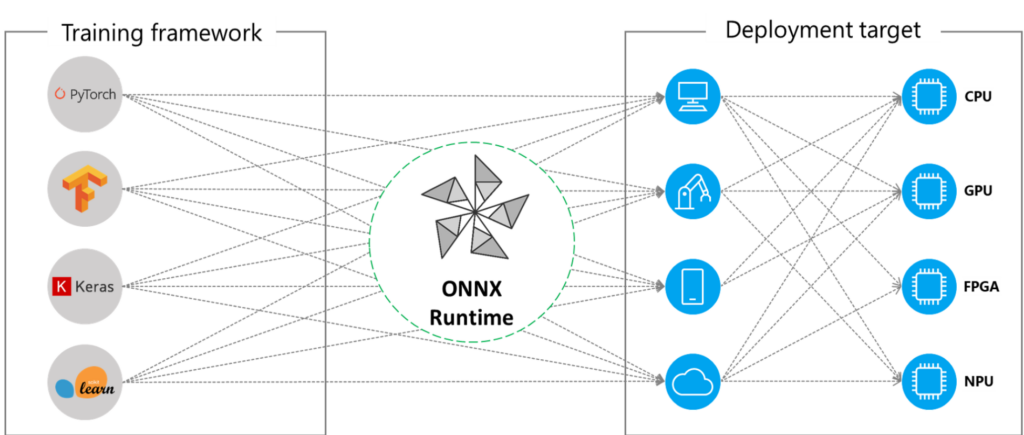
Developers can take advantage of a wide selection of EPs optimized for various hardware architectures by utilizing the “GetCapability()” interface in ONNX Runtime. Additionally, this interface enables developers to easily customize and configure their machine learning models to execute on the most suitable hardware platform for their specific use case, optimizing the performance, minimizing the latency and reducing the energy consumption.
Execution Providers List
| Execution Providers | Description |
| Intel DNNL | Uses Intel’s Deep Neural Network Library (DNNL) to accelerate inference on Intel CPUs. It contains vectorized and threaded building blocks that you can use to implement deep neural networks (DNN) with C and C++ interfaces. |
| TVM | Enables ONNX Runtime users to leverage Apache TVM model optimizations. It’s been tested to work on a handful of models on Linux and Windows, but not on MacOS. |
| Intel OpenVINO | Uses Intel’s OpenVINO toolkit to optimize inference performance on Intel CPUs, GPUs, and VPUs. |
| XNNPACK | Enables users to accelerate ONNX models on Android/iOS devices and WebAssembly. It is a highly optimized library of floating-point neural network inference operators for ARM, and x86 platforms. |
| NVIDIA CUDA | Uses NVIDIA’s CUDA toolkit to execute models on GPUs. |
| NVIDIA TensorRT | Leverages NVIDIA’s TensorRT Deep Learning inferencing engine to accelerate the inference on NVIDIA GPUs. |
| DirectML | Uses Microsoft’s DirectML API to accelerate inference on Windows devices that support DirectX 12. It provides GPU acceleration for ML tasks across a broad range of supported hardware and drivers. |
| AMD MIGraphX | Uses AMD’s Deep Learning graph optimization engine to accelerate the inference on AMD GPUs. |
| AMD ROCm | Enables hardware-accelerated computation on AMD ROCm-enabled GPUs. |
| ARM Compute Library | Accelerates the performance of ONNX model workloads across Armv8 cores. |
| Android Neural Networks API | Uses Android’s Neural Networks API to execute models on Android devices. |
| ARM-NN | Accelerates the performance of ONNX model workloads across Armv8 cores. |
| CoreML | Uses CPU, GPU, and Neural Engine to improve performance. |
| Rockchip NPU | Enables deep learning inference on Rockchip NPU via RKNPU DDK. |
| Xilinx Vitis-AI | Vitis-AI is Xilinx’s development stack for hardware-accelerated AI inference on Xilinx platforms, including edge devices and Alveo cards. |
| Huawei CANN | Helps users quickly build AI applications and services based on the Ascend platform. |
Quick Installation Guide in Python
In this quick guide, we will describe the process required in Python; please refer to the ORT’s documentation for other programming languages. With the model trained in ONNX format, you can perform inferencing with ONNX. Use the command below to install the GPU package:
pip install onnxruntime-gpu
Or use the package below if your code runs on Arm CPUs and/or macOS.
pip install onnxruntime
Now, create an inference session to work with your model.
import onnxruntime as ort
ORT_session = ort.InferenceSession("your_model.onnx")
Run the created inference session with the desired outputs and inputs to get the prediction.
Prediction = ORT_session.run(None, {"input1": value})
For more information, you can explore the ORT tutorials GitHub repo. These tutorials offer detailed explanations and practical examples of using ORT with ML frameworks and cloud services.
Highlights
Project Background
- Project: ONNX Runtime
- Author: Microsoft and Facebook
- Initial Release: September 2017
- Type: Machine Learning Accelerator
- License: MIT
- Contains: Set of libraries, executable installers, and a NuGet package manager.
- Language: C#, C++, C, Python, Assembly, Cuda, Java
- GitHub: microsoft/onnxruntime
- Runs On: Linux, Windows, and MAC
- Twitter: ONNXRuntime
- Stackflow: ONNXruntime
- Youtube: ONNX Runtime
Main Features
- It optimizes inference tasks of ML models for CPU and GPU.
- It supports various hardware and software platforms, including Windows, Linux, and macOS.
- It integrates various frameworks, such as PyTorch, TensorFlow, scikit-learn, and more.
- It is available in several programming languages.
- It supports a wide range of custom execution providers.
Prior Knowledge Requirements
- Knowledge of machine learning principles, neural networks, and deep learning architectures.
- Familiarity with the Open Neural Network Exchange (ONNX) format.
- Basic knowledge of programming languages, such as C#, C++, C, Python, Assembly, Cuda, and Java.
- Familiarity with data structures, such as arrays, tensors, and DataFames.
- Familiarity with platforms on which you intend to deploy your models.
Projects and Organizations Using ORT
- Adobe: “With ONNX Runtime, Adobe Target got flexibility and standardization in one package: flexibility for our customers to train ML models in the frameworks of their choice, and standardization to robustly deploy those models at scale for fast inference, to deliver true, real-time personalized experiences.” –Georgiana Copil, Senior Computer Scientist, Adobe.
- AMD: “The ONNX Runtime integration with AMD’s ROCm open software ecosystem helps our customers leverage the power of AMD Instinct GPUs to accelerate and scale their large machine learning models with flexibility across multiple frameworks.” –Andrew Dieckmann, Corporate Vice President and General Manager, AMD Data Center GPU & Accelerated Processing.
- Ant Group: “Using ONNX Runtime, we have improved the inference performance of many computer vision (CV) and natural language processing (NLP) models trained by multiple deep learning frameworks. These are part of the Alipay production system. We plan to use ONNX Runtime as the high-performance inference backend for more deep learning models in broad applications, such as click-through rate prediction and cross-modal prediction.” –Xiaoming Zhang, Head of Inference Team, Ant Group.
- Intel: “We are excited to support ONNX Runtime on the Intel® Distribution of OpenVINO™. This accelerates machine learning inference across Intel hardware and gives developers the flexibility to choose the combination of Intel hardware that best meets their needs from CPU to VPU or FPGA.” –Jonathan Ballon, Vice President and General Manager, Intel Internet of Things Group.
- Oracle: “The ONNX Runtime API for Java enables Java developers and Oracle customers to seamlessly consume and execute ONNX machine-learning models, taking advantage of the expressive power, high performance, and scalability of Java.” –Stephen Green, Director of Machine Learning Research Group, Oracle.
- Source: ORT community
Community Benchmarks
- 8,300 Stars
- 1,900 Forks
- 460+ Code contributors
- Source: GitHub
Releases
- ONNX Runtime v1.14.0 (2-2023); Update: Improves memory efficiency by enabling GPU memory reuse across different streams.
- ONNX Runtime v1.13.1 (10-24-2022); Update: Expose all arena configs in Python API in an extensible way.
- ONNX Runtime v1.12.0 (7-21-2022); Update: Support for invoking individual ops without the need to create a separate grap.
- ONNX Runtime v1.11.0 (3-26-2022):;Update: Memory utilization related performance improvements.
- Source: releases.
References
[1] GitHub.
[2] onnxruntime.ai