urllib
Urllib is a Python-based package that allows users to access and interact with URLs (Uniform Resource Locator). This package is divided into four modules oriented to access websites, download and parse data, modify URLs, handle errors, and more.
Components and Modules
Request
This module is used for opening and reading URLs. In other words, users can retrieve data from URLs by using HTTP, HTTPS, and FTP protocols. It supports basic and digest authentication, redirections, cookies, and more. The “.urlopen()” function allows users to establish a connection to a given website, while the “.read()” function allows the reading of its source code.
This module also comprises other functions and classes such as “.install_opener(),” “.build_opener(),” “.pathname2url()”, “.url2pathname()”, “.getproxies(),” “.Request()”, “.OpenerDirector()”, “.BaseHandler()”, and more. For more information about these functions, see the documentation.
Parse
The “urllib.parse” module was created to adhere to the Internet standards in accordance with the RFC (Request for Comments) requirements on Uniform Relative Resource Locators. It ensures compatibility and interoperability with various URL schemes, including ftp, gopher, hdl, http, https, imap, mailto, and more.
In general, this module allows breaking a URL into components such as addressing scheme, network location, queries, and more. For example, it is useful when users need to create new URLs given a “base URL.”
All functions in this module can be divided into two categories defined as URL parsing and URL quoting. The functions in URL parsing are designed to split URLs or combine resulting components into new URLs. Whereas the main goal of URL quoting functions is to take data for use as URL components by quoting special characters. These functions also facilitate the reverse process, allowing users to recreate original data from URL components by providing appropriate operations.
Error
The “urllib.error” module was designed to handle exception classes raised by the “urllib.request” module. It includes three simple functions defined as “.URLError()” that allows handling exceptions when it encounters a problem, “.HTTPError()” to handle specific HTTP errors (e.g., authentication requests), a subclass of “.URLError()”, and “.ContentTooShortError()” to handle exceptions when the “.urlretrieve()” function detects that the amount of the downloaded data is less than the expected amount.
Robotparser
This module parses robots.txt files, which specify what pages can be crawled by the search engines. It provides a single class called “.RobotFileParser()”, which was designed to determine whether a specific user agent can get access to a URL on a website based on the content of its robots.txt file.
Urllib vs. Similar Python Packages
When developers search for tools specialized in URL management, it’s common to come across multiple libraries with similar names; however, they don’t essentially share their origin and functionality. The most known libraries are urllib, urllib2, and urllib3.
urllib
It is the first urllib version, which has become obsolete since its introduction in Python 1.4. It was initially built to provide access to URLs and their subsequent reading. This package comprised the functions “.urlopen(),” “.urlretrieve(),” “.urlcleanup(),” “.quote(),” and “.unquote().”
urllib2
The urllib2 was built to replace its predecessor, providing extra features such as request, HTTPRedirectHandler, and OpenerDirector classes. It appeared integrated initially into Python 1.6.
urllib in Python 3
The urllib package in Python 3 just shares the name with its first version. It contains enhancements from its older versions, making it more efficient for working with HTTP requests and responses. More details are covered in this article.
urllib3
Despite the similarities with the previous ones, this package is unrelated to the Python standard library (third-party package). Andrey Petrov built this package as a powerful and user-friendly HTTP client for Python, providing missed features from the standard libraries such as thread safety, connection pooling, client-side SSL/TLS verification, and more.
Quick Installation Guide
Starting with the Python 3.0 version, urllib is already added to the standard library, so you don’t need to install additional packages to use it. However, it is a good practice to ensure that the package is installed and accessible to your Python environment. For conda users, use the following command in the Anaconda prompt:
conda list
It will print a list, and you will be able to see the “urllib” package. Look at these tutorials to install Anaconda in Windows and Ubuntu. Alternatively, you can use the pip package manager.
pip list
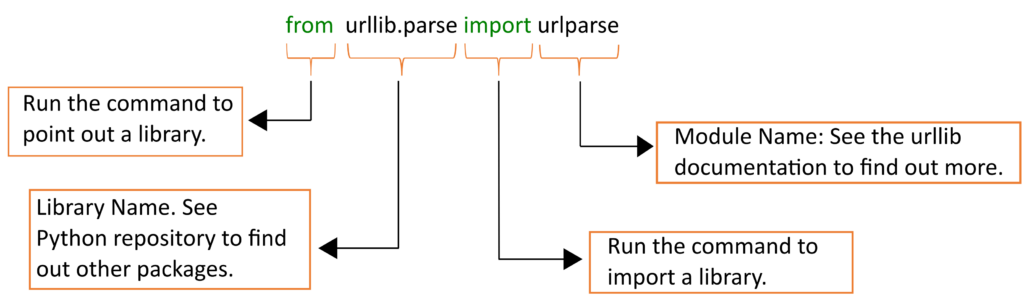
Assuming the package is already installed, you can import it into your code using the import statement.
from urllib.request import urlopen from urllib.parse import urlparse
Urllib Fundamentals
Using urllib.request
Use the “urlopen” function from the “urllib.request” module to create a connection and make a request to a specific URL. Once the connection is successfully established, use the “.read()” function to retrieve and read the HTML source code of the specified URL.
#PYNOMIAL - 2023 # import the "urlopen" function from the "urllib.request" module from urllib.request import urlopen myURL="http://www.google.com/" # Fetch the content of the webpage URL_data = urlopen(myURL) print(URL_data.read())
Using urllib.parse
Use the “urlparse” function to extract information from a URL. The components that this package extracts include the protocol scheme (scheme) such as “HTTP,” “HTTPS,” or “FTP,” the network location (Netloc) that specifies the domain name or IP address, the path of the URL (Path) that specifies the resource on the server which includes directories or filenames, and finally, the Query string (Query) which is used to pass additional data to the server.
#PYNOMIAL - 2023
# import the "urlparse" function from the "urllib.parse" module
from urllib.parse import urlparse
myURL="https://www.python.org/about/help/"
# Parse the URL into its components
parsedURL = urlparse(myURL)
# Extract the scheme, netloc, path, and query components
scheme = parsedURL.scheme
netloc = parsedURL.netloc
path = parsedURL.path
query = parsedURL.query
# Print the extracted components
print('Scheme:', scheme)
print('Netloc:', netloc)
print('Path:', path)
print('Query:', query)
Using urllib.error
Use the “HTTPError” and “URLError” functions to handle errors when working with URLs. In the following example, we have intentionally modified an URL to return an HTTP error (404 Not Found). These function conditions allow users to make their code more robust and resilient to unexpected situations.
#PYNOMIAL - 2023
# import the "urlopen", "HTTPError", and "URLError" functions
from urllib.request import urlopen
from urllib.error import HTTPError, URLError
myURL = "https://www.python.org/notfound"
try:
# Attempt to open a connection to the URL and fetch the content
URL_data = urlopen(myURL)
except HTTPError as e:
# Handle HTTP errors (e.g., 404 Not Found)
print('HTTP Error:', e.code, e.reason)
except URLError as e:
# Handle URL errors (e.g., bad URL)
print('URL Error:', e.reason)
else:
# If no error occurred, read and print the content of the response
print(URL_data.read())
Highlights
Project Background
- Project: urllib
- Author: –
- Initial Release: 2019
- Type: HTTP client for Python
- License: –
- Contains: request, parse, error, and robotparser
- Language: Python 3
- GitHub: –
- Runs On: Linux, Windows, MacOS
- Twitter: –
Main Features
- Urllib allows users to access and interact with websites from your Python environment.
- It facilitates the connection to a web page through a code snippet.
- The parse module simplifies the manipulation of a URL and its components.
- It provides helper classes to check for HTTP or URL errors.
- Uillib in Python 3 contains enhancements from its older versions.
Prior Knowledge Requirements
Here are a few tips to effectively use this library:
- Have a basic understanding of the Python programming language.
- Know basic URLs concepts such as protocol scheme, domain name, path, and query string.
- Have a basic understanding of the HTTP and FTP protocols.
Community Benchmarks
- – Stars
- – Forks
- – Code contributors
- – releases
Versions
- urlllib in Python 3 – It is the newest package, developed from older versions.
- urlllib2 in Python 1.6 – It replaces its predecessor, providing extra features.
- urlllib in Python 1.4 – It provides access to URLs and their subsequent reading. It is an obsolete package.